HazelCast
入门简介
1. HazelCast是什么

Hazelcast 是由Hazelcast公司开发的一款
开源的分布式内存级别的缓存数据库
可以为基于JVM环境运行的各种应用
提供分布式集群和分布式缓存服务
##

in-memory data grid

在国外项目中使用较为广泛
交易系统应用较多 其中有很多银行客户
SonarQube集群方案也是基于Hazelcast实现
2. 主要特性
按应用分布式
数据按照某种策略尽可能均匀的
分布在集群的所有节点上
数据会尽量“靠近”应用存放
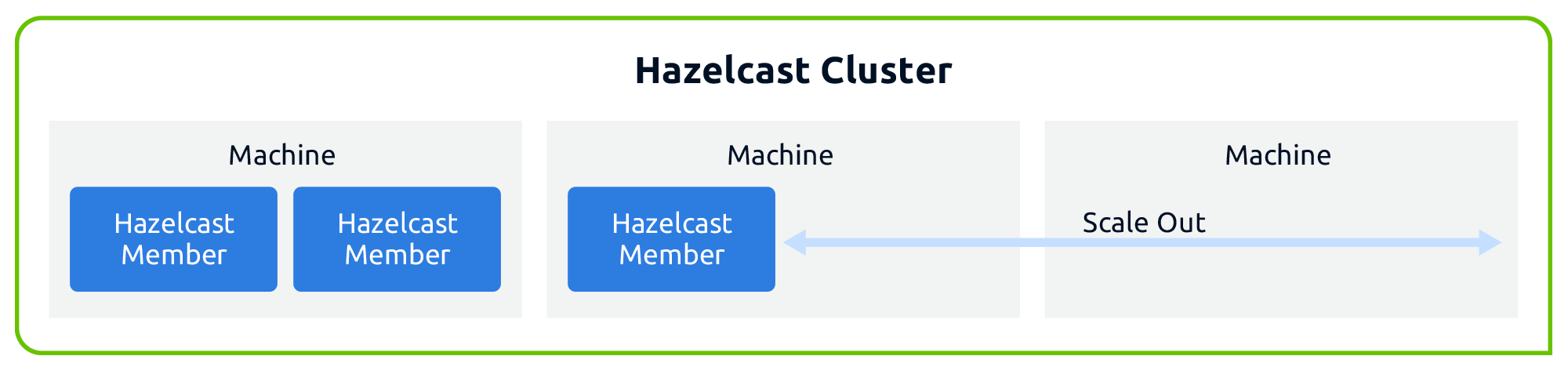
自治集群(无中心化)
Hazelcast 没有中心节点
集群中最老的节点负责发送分区表
可扩展的
每个节点都有可能随时退出或随时进入
能按照业务需求增加或者减少服务节点
集群中存储的数据都会有一个备份
简单易用
数据模型是面向对象和非关系型的
提供了常用 Java 数据结构接口的分布式实现
Hazelcast 的所有功能只需引用一个jar包
数据结构
Non-partitioned 不分区
该类型数据结构没有分区概念
但是能够多副本 整个数据集在一个或者多个节点
- Map
- MultiMap:
<key,List<T>>类型的数据结构 - Cache
- PN Counter: 分布式计数器
- Event Journal:事件日志
Partitioned 分区
支持分片的数据结构数据集
分散的分布在集群的多个节点上的
- Queue
- Set
- List
- Ringbuffer
- Lock
- ISemaphore
- IAtomicLong
- IAtomicReference
- FlakeIdGenerator
- ICountdownLatch
- Cardinality Estimator(基数估算器)
Hazelcast分区
Hazelcast 服务之间是端对端,没有主从之分
集群中所有的节点都存储等量的数据以及进行等量的计算
Hazelcast 默认情况下把数据存储在 271 个区上
Hazelcast分区存储原理
- 先序列化此键或对象名称,得到一个byte数组;
- 然后对上面得到的byte数组进行哈希运算;
- 再进行取模后的值即为分区号;
- 最后每个节点维护一个分区表,存储着分区号与节点之间的对应关系,这样每个节点都知道如何获取数据
Hazelcast集群实现原理
通过分片来存储和管理所有进入集群的数据
分片保证数据可以快速被读写
通过冗余保证数据不会因节点退出而丢失
分片
Hazelcast的每个数据分片(shards)
被称为一个分区(Partitions)
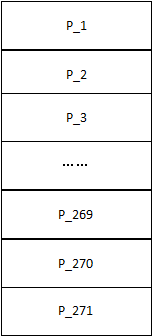
只有一个节点时
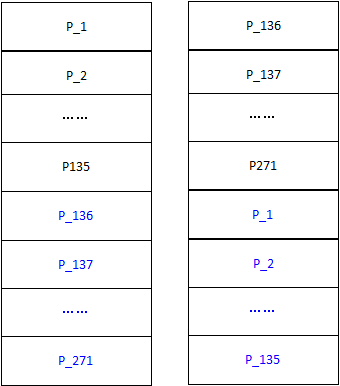
两个节点时
节点变动会触发重分区和数据平衡操作
每个成员的数据分片都至少有一个副本

更多节点时
拓扑结构
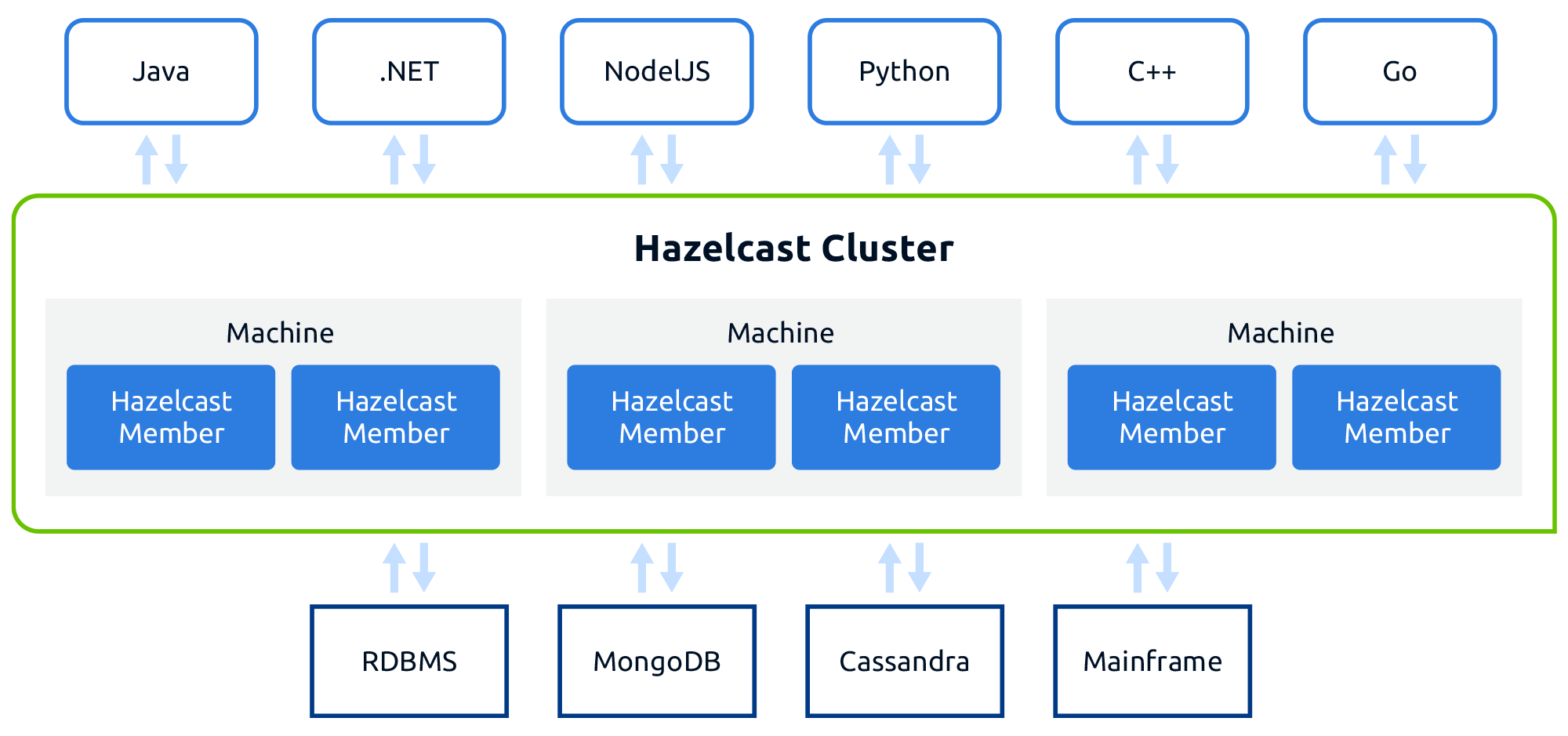
基本架构模型
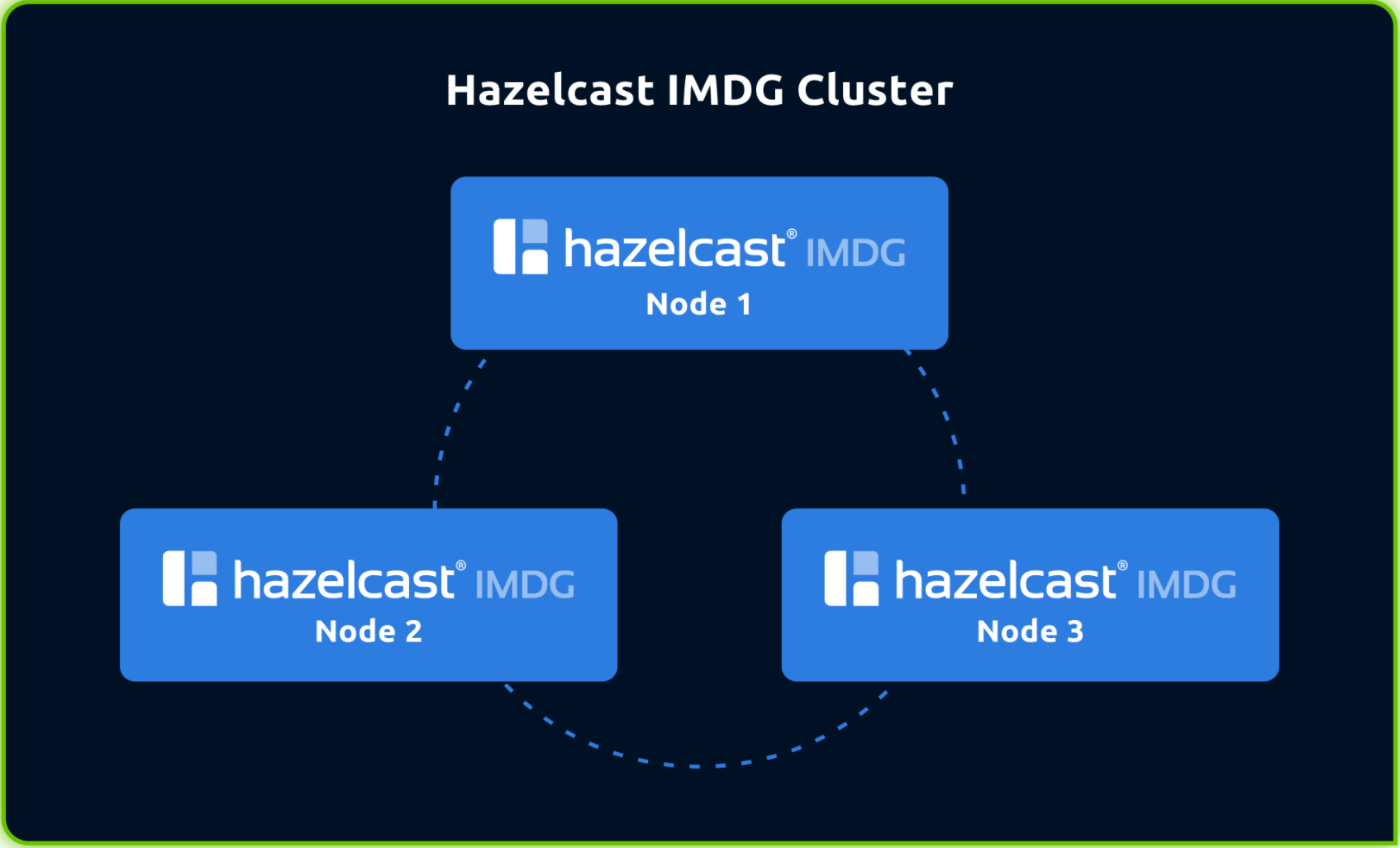
嵌入式拓扑模型
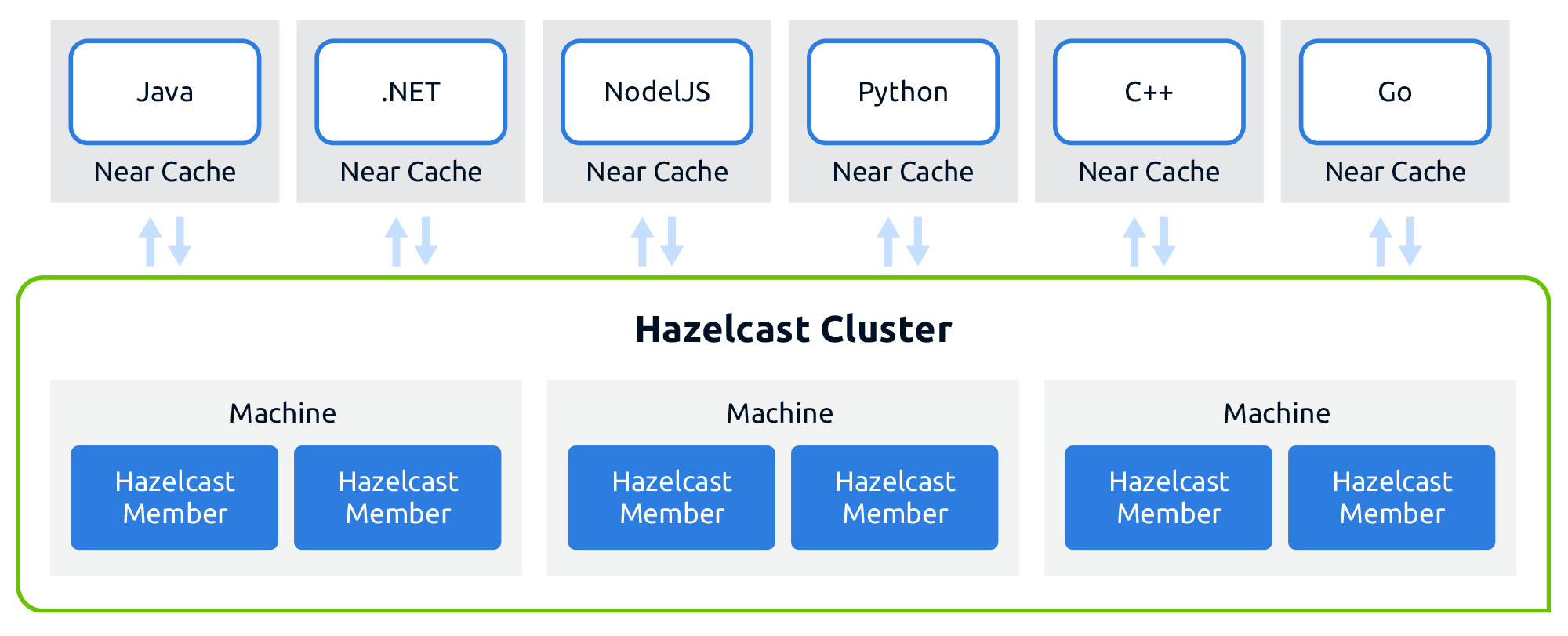
C/S 客户端/服务器 模型
支持近端缓存
Map 数据存储
OBJECT BINARY NATIVE
OBJECT
直接 java 对象
get 操作无需反序列化 得到的是对象的直接引用
与应用程序共享 jvm heap
Binary
java 对象的二进制格式
需要序列化与反序列化操作
与应用程序共享 jvm heap
NATIVE
使用 key / value 实现的序列化接口
将对象存储在堆外内存或者从堆外内存读取
不与应用程序共享内存
在数据量大的场景中
通常会使用 NATIVE 格式的存储数据
以减少应用程序 jvm gc 压力
序列化接口
- java.io.Serializable
- java.io.Externalizable
- com.hazelcast.nio.serialization.DataSerializable
- com.hazelcast.nio.serialization.IdentifiedDataSerializable
- com.hazelcast.nio.serialization.Portable
- Custom Serialization (using StreamSerializer and ByteArraySerializer).
- Global Serializer: Please see the Global Serializer section for details
使用 hazelcast 提供的接口通常能获得较好的性能
需要实现特定接口和服务器端配置
可以使用 thrift 等序列化框架
连接到 hazelcast 的序列化 I/O 流上
4. 数据亲密性
确保业务相关的数据在同一个集群节点上
避免操作多个数据的业务事务在通过网络请求数据
实现更低的事务延迟
通过接口将相关数据定位到相同节点
1 | public interface PartitionAware<T> { |
1 | final class OrderKey implements PartitionAware, Serializable { |
使用PartitioningStrategy自定义分区策略
1 | <hazelcast> |
CAP 支持
分布式数据库通常通过分区和多副本的方式
以实现扩展性,可用性和数据分布透明性
- 不用关心数据位置,像使用单一数据集一样使用整个数据集
- 数据集被切分成更多小分区,并且各自拥有独立副本
- 副本与leader数据集尽可能的均匀的分散在集群的不同节点上
均匀: 是指各个节点的数据规模均衡性,以保证节点性能平衡;分散: 是指 leader 与副本通常不会在一个相同的节点或者机架或者技术中心,以求最大的可用性;
通常分布式数据库 AP 优先
因为多个副本同时更新成功或者失败是一个及其复杂和困难的事情,除了需要一个高性能的分布式事务管理器,还需要应对各种复杂的网络和硬件故障,即便如此,在极端情况下的数据恢复也将是极大的挑战;
Hazelcast是一个 AP 系统
延迟复制 lazy replication
尽量一致
最终一致
layze replication: 根据 primary replication 的变更日志,在独立的事务中应用这些帮更到副本数据集上;尽量一致: 言外之意就是肯定会有不一致的情况。最终一致:在某个时间点差异存在复制滞后,后台会一直工作填补滞后
实战演示
1 | <dependency> |
引入依赖
创建控制器
1 |
|
1 | mvn spring-boot:run -Dspring-boot.run.jvmArguments="-Dserver.port=8081" |
启动集群
1 | Members {size:4, ver:4} [ |
1 | curl --data "key=key1&value=test1" "localhost:8081/put" |
写入和获取数据
更多
事务支持
- 支持事务的数据类型:Queue/Set/List, Map/Multimap
- Hazelcast 支持两种事务模型:
ONE_PHASE,TWO_PHASE
线程模型
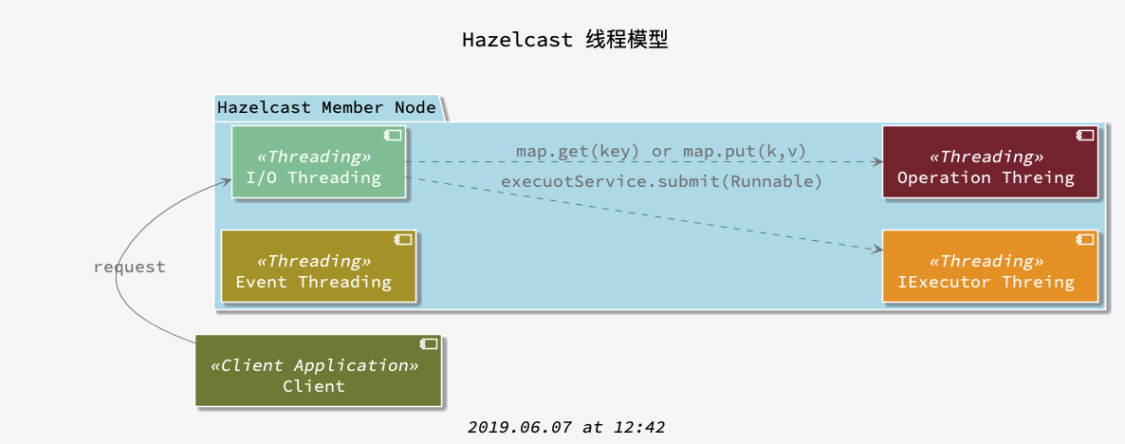
IO Threading (get put…)
Event Threading (Topic…)
IExecutor Threading (处理分布式任务)
Operation Threading (分区相关)
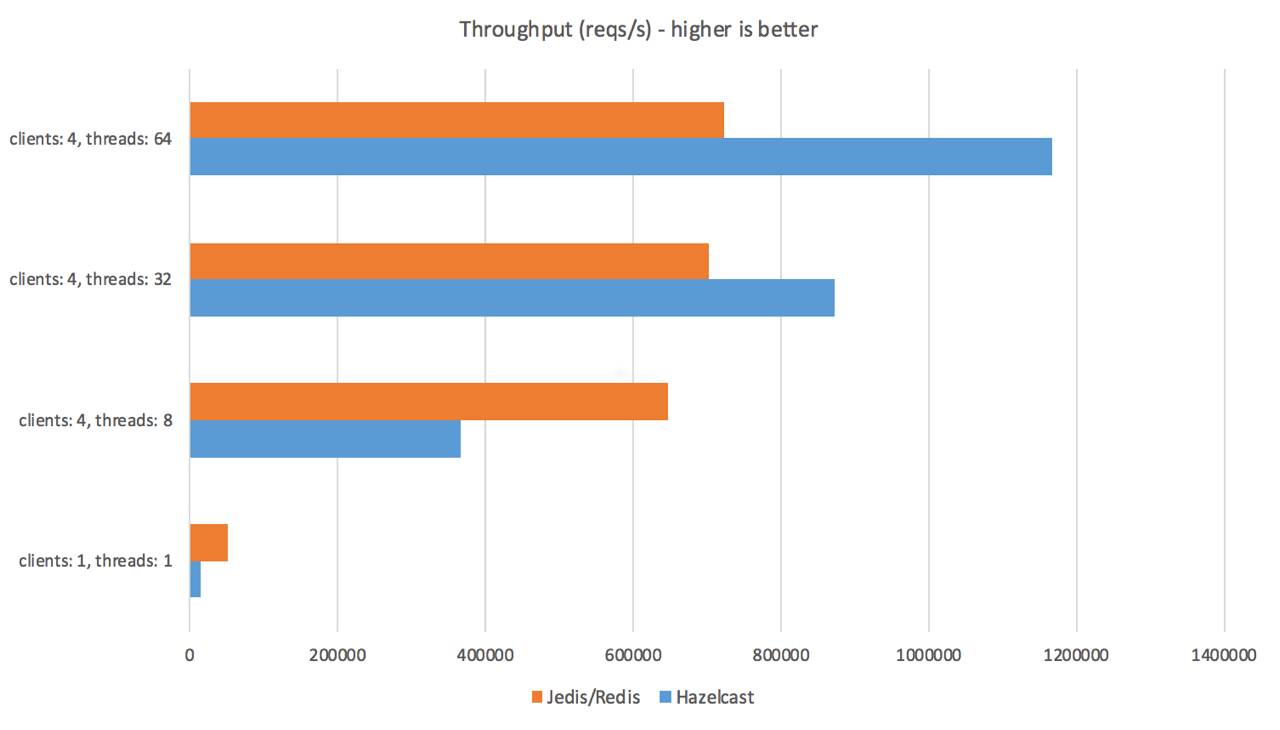
性能对比